Numina 代码解析与复现
唠唠闲话
代码复现
根据 AIMO 的规则,参赛队伍必须公开其代码、方法、数据和模型参数。作为第一届获胜者,Numina 团队开源了完整的训练代码、数据集及微调后的模型参数,以及最终求解问题的代码,确保工作完全可复现。此外,Numina 还在 HuggingFace 平台上托管了一个可以在线运行的推理服务(不过该服务目前挂了)。
环境准备
GitHub 代码地址:project-numina/aimo-progress-prize。
项目的代码库组织如下:
1 | aimo-progress-prize/ |
创建 Python 环境,并安装相关依赖:
1 | conda create -n aimo python=3.10 && conda activate aimo |
模型训练
Numina 的模型训练分为两个主要阶段,每个阶段都采用 DeepSpeed ZeRO-3 协议进行模型分片,并使用 8 个具有 80GB 显存的 GPU 进行全量微调。
-
第一阶段:使用 NuminaMath-CoT 数据集对 DeepSeekMath-Base 7B 模型进行 SFT(监督微调),得到模型 NuminaMath-7B-CoT :
1
accelerate launch --config_file=training/configs/deepspeed_zero3.yaml training/sft.py training/configs/stage-1-cot.yaml
-
第二阶段:在 NuminaMath-TIR 数据集上对第一阶段的 SFT 模型进行进一步微调,学习工具集成推理(Tool-Integrated Reasoning),最终得到一个能够结合语言推理和 Python 代码执行的 “推理代理” 模型 NuminaMath-7B-TIR :
1
accelerate launch --config_file=training/configs/deepspeed_zero3.yaml training/sft.py training/configs/stage-2-tir.yaml
-
后处理量化:优化模型在 Kaggle 的 T4 GPU 上的运行效率,Numina 对模型进行了 8-bit 量化,使用 AutoGPTQ 降低计算资源需求。
1
python training/quantization.py --model_id AI-MO/NuminaMath-7B-TIR --calibration_dataset data/NuminaMath-TIR
该模型不支持 Inference API 不能白嫖 HuggingFace 的 GPU 资源,可以在本地用 vLLM 运行,启动脚本:
1 | python -m vllm.entrypoints.openai.api_server \ |
模型推理
使用 vLLM 推理。
解构代码,我们用 API 替代。
分两个部分,一个是 sample 的数目,一个是执行代码的轮次。
Gradio 演示
官方提供了演示 Demo:https://huggingface.co/spaces/AI-MO/math-olympiad-solver
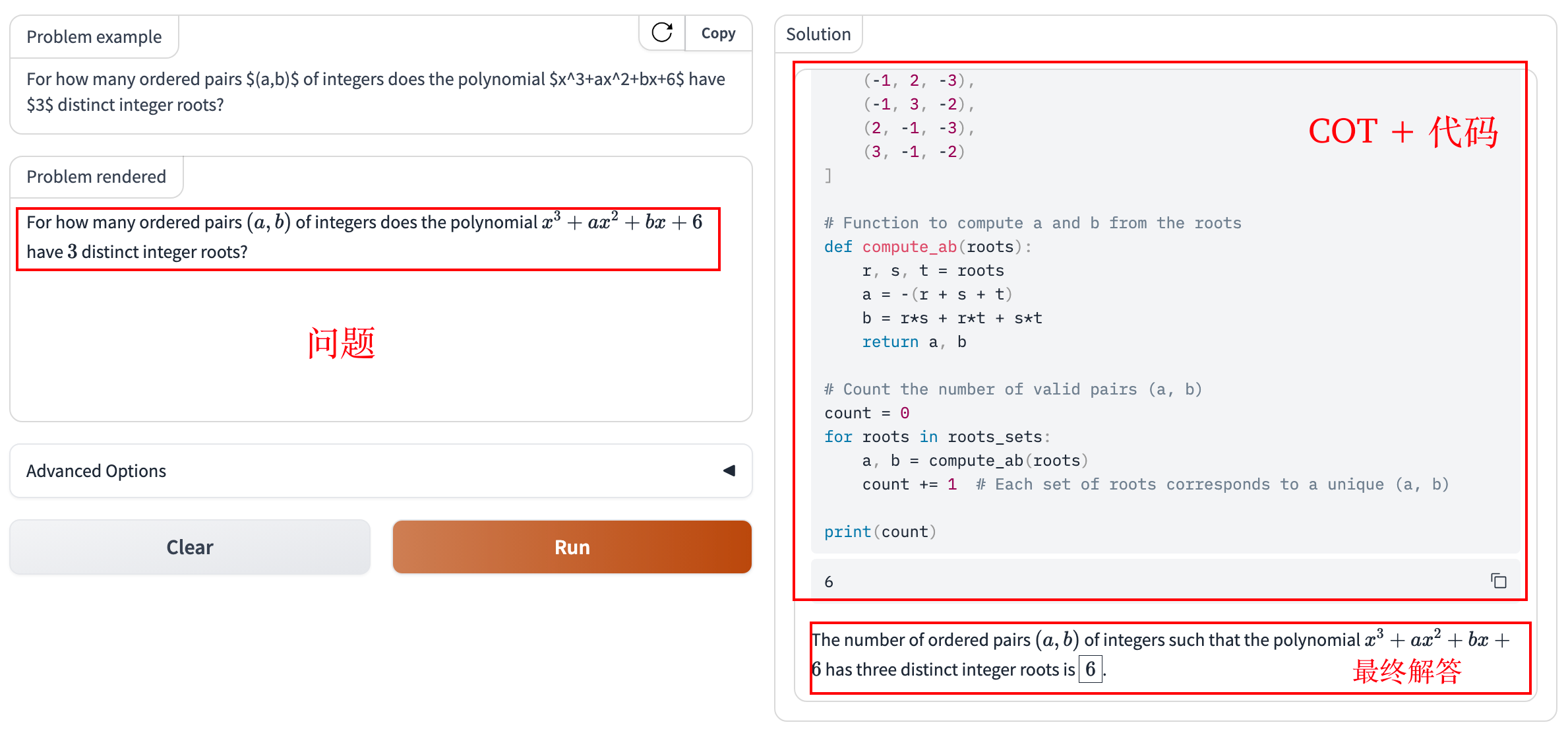
该托管服务已经删除了。我们重写一个 Gradio 服务。
示例测试。