唠唠闲话
配置 Kaggle
安装 Kaggle 的 Python 包,用于下载竞赛代码和公开的笔记本:
下载需要鉴权,在 Kaggle 个人设置页,下载密钥:
将密钥文件 kaggle.json 放到 ~/.kaggle 目录下。
Kaggle 运行代码的工作区为 /kaggle 目录,输入通常放在 input 目录,当前 notebook 所处的目录为 working,模型输出文件,提交结果通常放在 output 。
特别地,sys.path 会根据具体竞赛添加相关代码所在的目录,以便直接在当前工作区 import。
比如 AIMO2 的情况:
输出:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| ['/kaggle/lib/kagglegym',
'/kaggle/lib',
'/kaggle/input/ai-mathematical-olympiad-progress-prize-2',
'/opt/conda/lib/python310.zip',
'/opt/conda/lib/python3.10',
'/opt/conda/lib/python3.10/lib-dynload',
'',
'/root/.local/lib/python3.10/site-packages',
'/opt/conda/lib/python3.10/site-packages',
'/root/src/BigQuery_Helper',
'/kaggle/input/ai-mathematical-olympiad-progress-prize-2/kaggle_evaluation',
'/kaggle/input/ai-mathematical-olympiad-progress-prize-2/kaggle_evaluation/core/generated',
'/kaggle/input/ai-mathematical-olympiad-progress-prize-2/kaggle_evaluation/core',
'/kaggle/input/ai-mathematical-olympiad-progress-prize-2/kaggle_evaluation/core/generated']
|
提交指南
模板代码
下载竞赛的模板代码:
1
| kaggle kernels pull ryanholbrook/aimo-2-submission-demo
|
这个 Jupyter Notebook 介绍了竞赛规范:要求设置一个评估 API 的服务,用以响应推理请求。在对隐藏测试集进行评估时,由 aimo_2_gateway 定义的客户端将在一个不同的容器中运行,能够直接访问隐藏测试集,并依次以随机顺序处理每一个问题。
相关逻辑在模板中定义好了,只需编写预测函数:
- 将下边函数替换为推理代码
- 该函数应返回一个在 0 到 999 之间的整数
- 除首次预测外,每个预测必须在问题提供后的 30 分钟内返回。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| import os
import pandas as pd
import polars as pl
import kaggle_evaluation.aimo_2_inference_server
def predict(id_: pl.DataFrame, question: pl.DataFrame) -> pl.DataFrame | pd.DataFrame:
"""Make a prediction."""
id_ = id_.item(0)
question = question.item(0)
prediction = 0
return pl.DataFrame({'id': id_, 'answer': 0})
inference_server = kaggle_evaluation.aimo_2_inference_server.AIMO2InferenceServer(predict)
if os.getenv('KAGGLE_IS_COMPETITION_RERUN'):
inference_server.serve()
else:
inference_server.run_local_gateway(
(
'/kaggle/input/ai-mathematical-olympiad-progress-prize-2/test.csv',
)
)
|
注意事项:提交后在隐藏测试集上运行时,需在启动后 15 分钟内调用 inference_server.serve(),否则网关将会抛出错误。如果加载模型需要超过 15 分钟,可以在首次预测调用中加载,因为首次调用不受 30 分钟响应期限的限制。
搭建本地环境
查看竞赛模板的工作目录,容易发现 input 下存在一个评估代码 ai-mathematical-olympiad-progress-prize-2。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
/kaggle
|-- input
| `-- ai-mathematical-olympiad-progress-prize-2
| |-- AIMO_Progress_Prize_2_Reference_Problems_Solutions.pdf
| |-- kaggle_evaluation
| | |-- __init__.py
| | |-- aimo_2_gateway.py
| | |-- aimo_2_inference_server.py
| | `-- core
| | |-- __init__.py
| | |-- base_gateway.py
| | |-- generated
| | | |-- __init__.py
| | | |-- kaggle_evaluation_pb2.py
| | | `-- kaggle_evaluation_pb2_grpc.py
| | |-- kaggle_evaluation.proto
| | |-- relay.py
| | `-- templates.py
| |-- reference.csv
| |-- sample_submission.csv
| `-- test.csv
|-- lib
| `-- kaggle
| `-- gcp.py
`-- working
|
这是竞赛官方的代码接口,可以通过命令下载查看:
1
| kaggle competitions download -c ai-mathematical-olympiad-progress-prize-2
|
将私有数据集替换提交的 test.csv 文件,之后就可以在本地调试了。
1
2
3
4
5
6
7
8
9
| inference_server = kaggle_evaluation.aimo_2_inference_server.AIMO2InferenceServer(predict)
if os.getenv('KAGGLE_IS_COMPETITION_RERUN'):
inference_server.serve()
else:
inference_server.run_local_gateway(
(
'/kaggle/input/ai-mathematical-olympiad-progress-prize-2/test.csv',
)
)
|
简单示例
下边举一个提交例子,用 vLLM 运行原始的 DeepSeek-7b 模型,实测能答对两题。
下载示例代码:
1
| kaggle kernels pull tianjiajun177/aimo2-vllm-deepseek-math-7b-instruct-infer-l4-4
|
选择计算配置为 GPU L4 * 4:
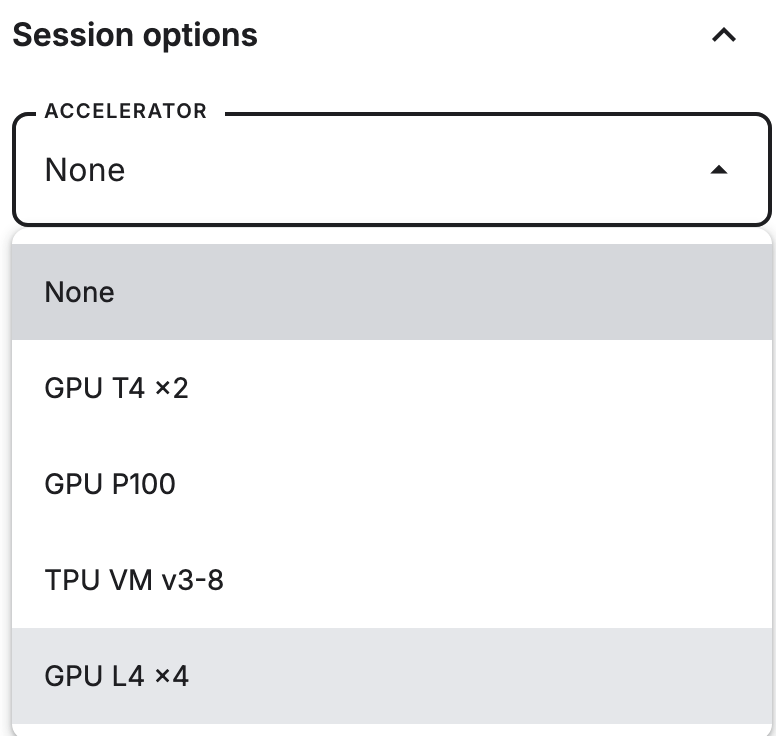
显存大小为 23G * 4,这个大小能运行量化的 72B 模型,但每周只有 30 h 运行时间。
展开 input 选项卡,添加对应模型参数:
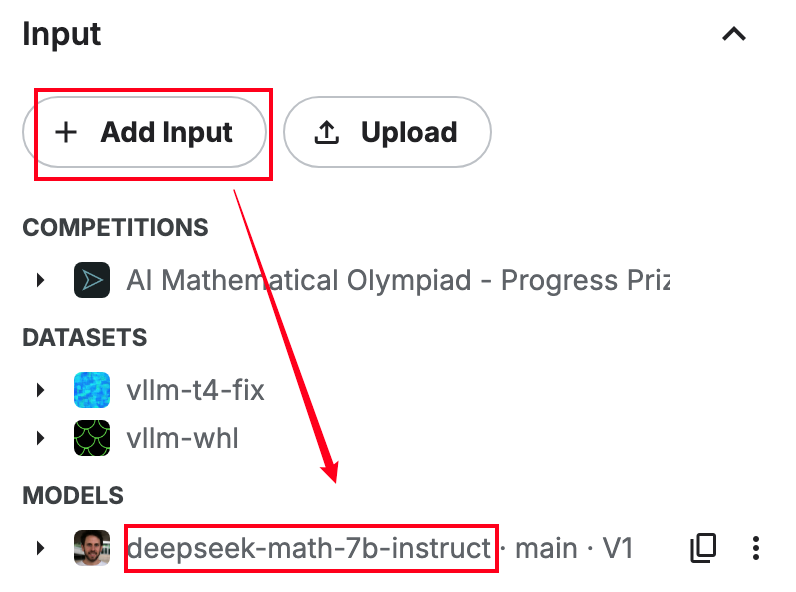
此时 input 目录多了 deepseek 模型:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
/kaggle/
|-- input
| |-- deepseek-math-7b-instruct
| | `-- transformers
| | `-- main
| | `-- 1
| | |-- LICENSE
| | |-- README.md
| | |-- config.json
| | |-- generation_config.json
| | |-- model-00001-of-00002.safetensors
| | |-- model-00002-of-00002.safetensors
| | |-- model.safetensors.index.json
| | |-- tokenizer.json
| | `-- tokenizer_config.json
|
先配置 vLLM 推理服务:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
llm = vllm.LLM(
"/kaggle/input/deepseek-math-7b-instruct/transformers/main/1",
tensor_parallel_size=4,
gpu_memory_utilization=0.95,
trust_remote_code=True,
dtype="half",
enforce_eager=True,
swap_space=2,
)
tokenizer = llm.get_tokenizer()
def generate_text_vllm(requests, tokenizer, model):
sampling_params = vllm.SamplingParams(
temperature=0.00,
seed=42,
max_tokens=1024
)
responses = model.generate(requests, sampling_params=sampling_params, use_tqdm=False)
response_text_list = []
for response in responses:
response_text_list.append(response.outputs[0].text)
return response_text_list
|
然后来编写 predict 函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
tool_instruction = '\nPlease solve the problem above, and put your final answer within \\boxed{}.'
def predict(id_: pl.Series, question: pl.Series) -> pl.DataFrame | pd.DataFrame:
"""Make a prediction."""
id_ = id_.item(0)
question = question.item(0)
prompt = question + tool_instruction
generate_text = generate_text_vllm([prompt], tokenizer, llm)[0]
answer = 0
try:
result_output = re.findall(r'\\boxed\{(\d+)\}', generate_text)
answer = int(result_output[-1].strip()) % 1000
except:
print('error')
answer = random.randint(0, 999)
return pl.DataFrame({'id': id_, 'answer': answer})
|