Alphaproof 技术解析,策略及研究
AlphaProof 的技术分析,结合证明代码,社区帖子以及今年 ICLR 形式化相关研究。
变体生成
训练数据是形式化的难点,因此 AlphaProof 做了大量的数据合成。采用一种变体生成策略:
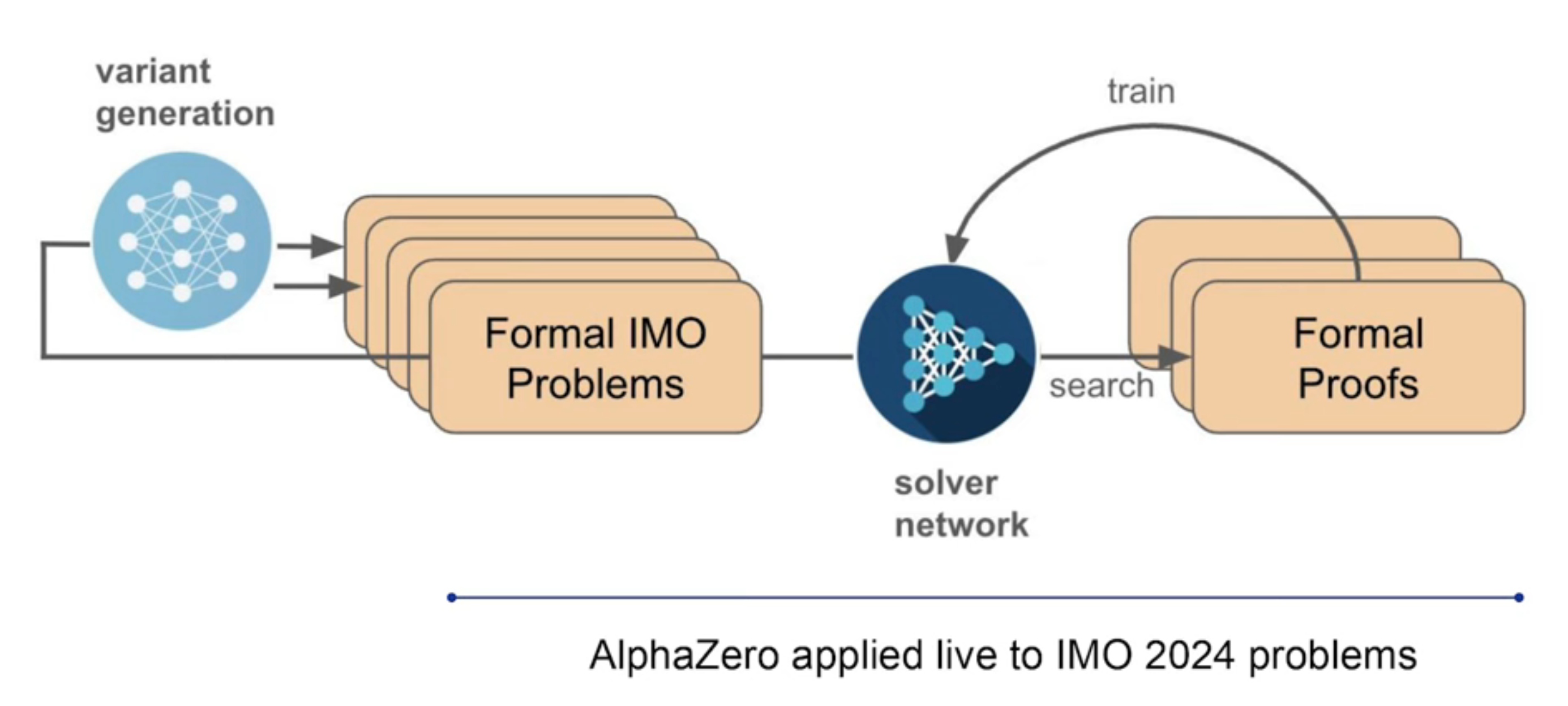
- 对每道 IMO 问题进行抽象化,通过修改或简化某些细节,生成上千个变体问题,构造了一系列从易到难的变体问题。
- 训练阶段,RL 模型接收问题作为信号,先从简单的变体问题开始,到逐步能求解困难题。最终求解了题库里 40% 的 IMO 竞赛题。
- 最终提交时,AlphaProof 最长花费三天时间,不断地解决简单版本的变体问题,直到求解最终问题。
- 解题存在简单模式和困难模式。前者由人类提供解答,让模型证明;后者需要模型自己寻找答案再证明。AlphaProof 遵循了困难模式:用 Gemini 生成候选答案,尝试证明对或错。到后边模型逐渐地学习如何否决大部分的错误命题,并专注到少了尝试。
- 不过在 IMO2024 竞赛中,仍使用了简单模式,即人类提供形式化的问题。
变体生成有两个技术点需要打通:
- 从易到难地构造变体问题
- 模型生成候选方案并否决错误命题,提升变体问题的质量
理论构建
AlphaProof 没能解答的两题均为组合题。这存在有多方面的因素:
一是,缺少组合相关的竞赛级别的问题,例如 minif2f,FIMO 只包含代数和数论题。
二是,组合问题的形式化,需要模型主动去构造概念,工具。就像Thomas Hubert 在报告提到,AlphaProof 缺少理论构建(Theory building)的能力。
AlphaProof 的证明使用很多 suffices 策略,比如:
1 | suffices:∑d in .range A,⌊x+d*x⌋=∑Q in .range A,(⌊x⌋+2*(Q * (l-.floor x))) |
通过“只需证 xxx”来转化目标,从后往前推导。
理论构建的要素是往前推导,从初始条件出发,生成引理,逐步扩充策略空间。
也即,policy 模型生成策略时,除了根据目标生成 tactic,也多根据条件生成引理结论。
关于这点,可以对照人类编写,已合并到 Mathlib 的 Q1,Q2,Q5,Q6,以及
从形式上看,AlphaProof 把所有证明写在一个过程中。大概因为大部分基准都是如此,给定问题,输出答案。或许可以借鉴人类的经验,避免给自己加难度。
比如:
1 | def Condition (a b : ℕ) : Prop := |
1 | lemma Aquaesulian.apply_apply_add (x : G) : f (f x + x) = f x + x |
可以对照 P2 题解和修改
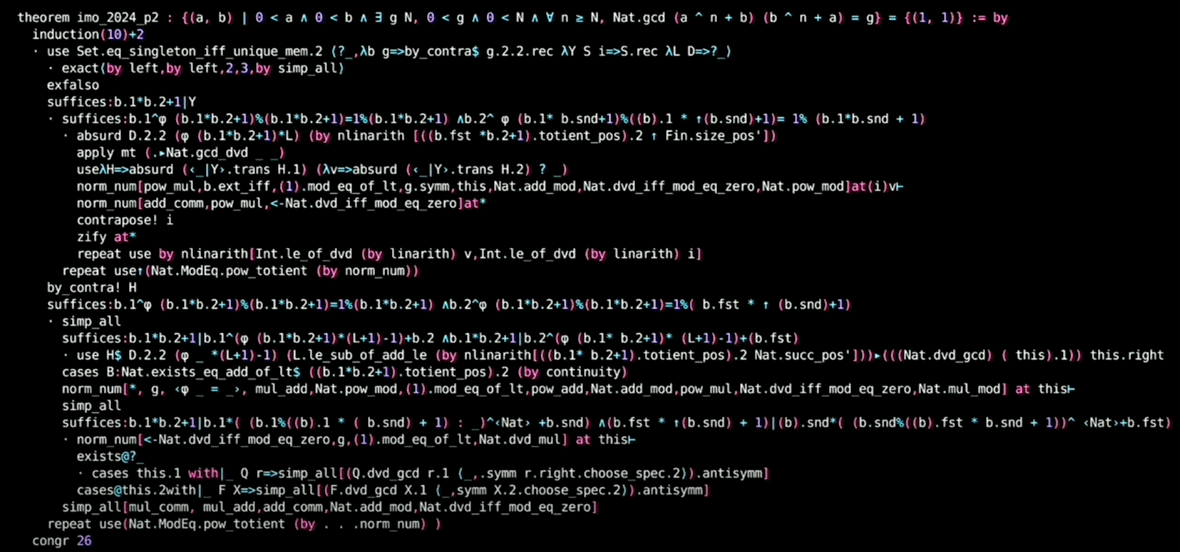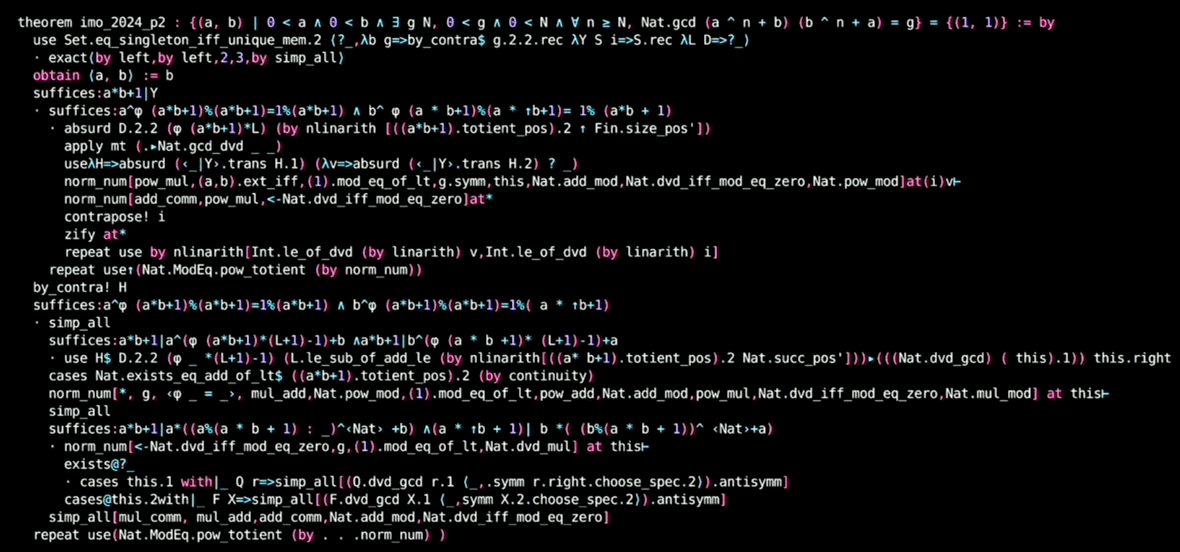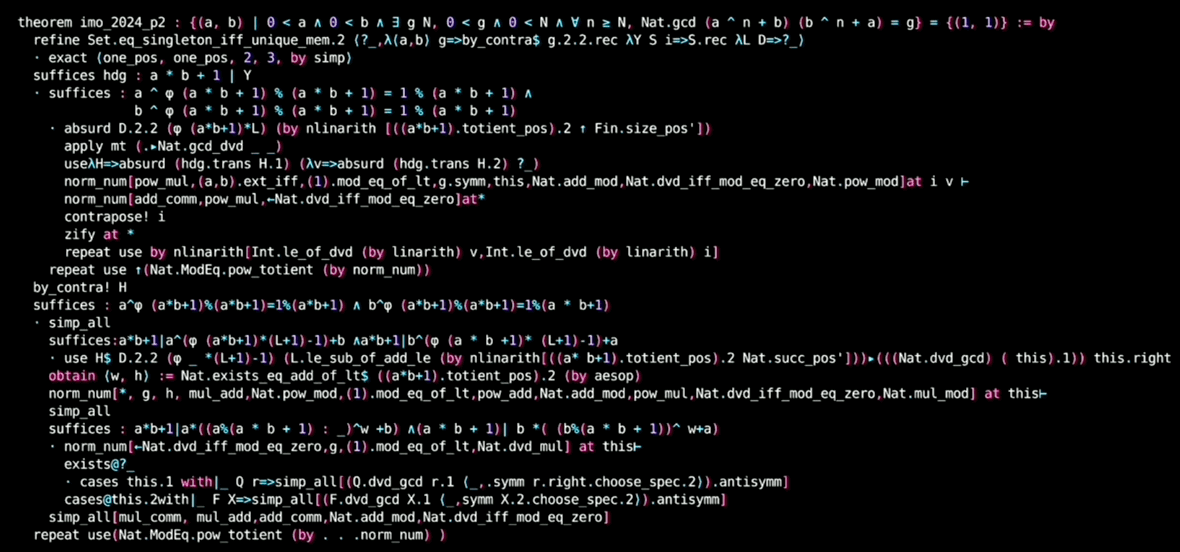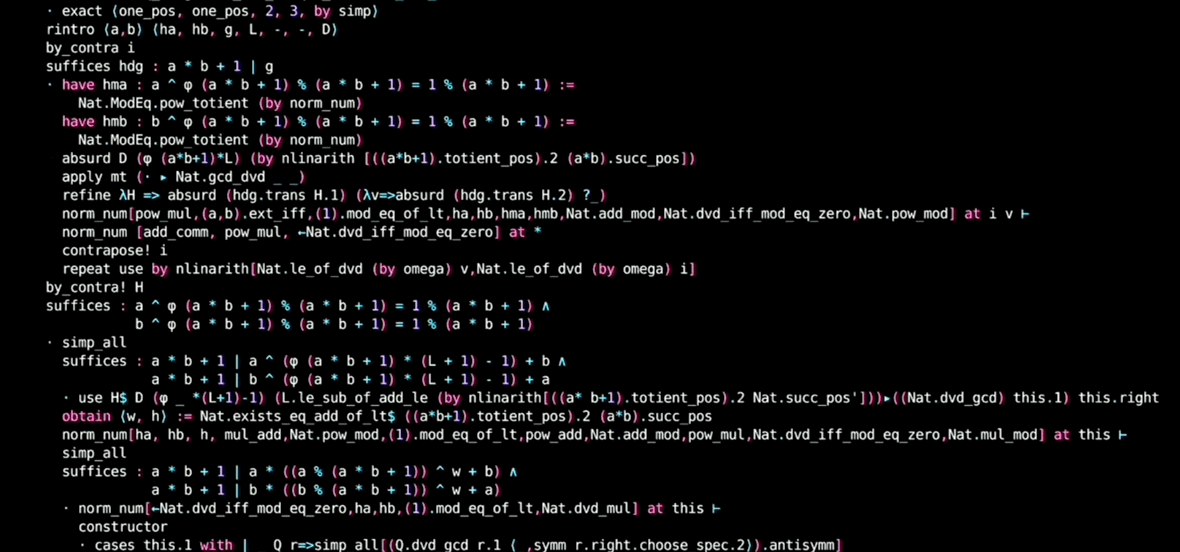
今年在 ICLR 上有一些相关研究:
组合问题
DeepMind 方法涉及将假设中的所有内容都放在一个定理陈述中,而不是有辅助定义。总体的证明模式是给一个问题,生成游戏解答。
设计一些构造,引理。证明过程也会进行整理,总结引理。
组合问题的缺陷,人类主动形式化。相关工作:社区人工标注,常见数据集。(数学家的工作不是证明东西,而是发明新的定义。然后用它们创建语句,然后证明这些语句。)
o1 思维
代码分析
潜在的问题,冗余引理,多余记号,混乱的缩进。像是 loosely 的 typecheck + symbol gen(结构化编码,我瞎猜的),而不是 sample premise。
人类做法,解题后,擦除做题过程,启发思路,探索思路。o1 相当于还原。
对于这点,AlphaProof 似乎给了原汁原味的探索过程。
无序是一个更好的状态
两阶段
AlphaProof 当前的缺陷。以及前边提到的,构建结构。
刻意地分出两个阶段:
o1,两阶段,探索和总结。探索可以玩出花,比如多智能体,自我反思对话,等等,放开思考方式,能力更灵活,找到它自己的风格,软件招。(比如 deepseek)
第二阶段,重构证明。
由薄到厚,由厚到薄。
一方面是对齐人类偏好,二是保存模型推理的自一致性,提升数据质量。
第二阶段的训练,包括 定理构建 能力等,这对处理更复杂的问题,可能有帮助。对已有知识进行消化,整理,理清脉络,再进一步推进。
就像 o1 不会把思考输出给用户。
hard to define,不一定更短。 一阶段的时候,最短并不一定是最好的!可以尽可能的扩展,提供材料。短了反而容易晦涩。比如大量运用 lambda 等。
比如,group some result,subgoals
另一个 trick,用一些反向合成的策略,或者一些激进的策略(比如,随机生成一些步骤,得到一个结论),或者以某种方式,得到一些结论。或者,以某种逻辑,宏观的构造解答。
另一个 trick,用编程集成,来促进计算推理的数据合成。 比如变体阶段。